Refer
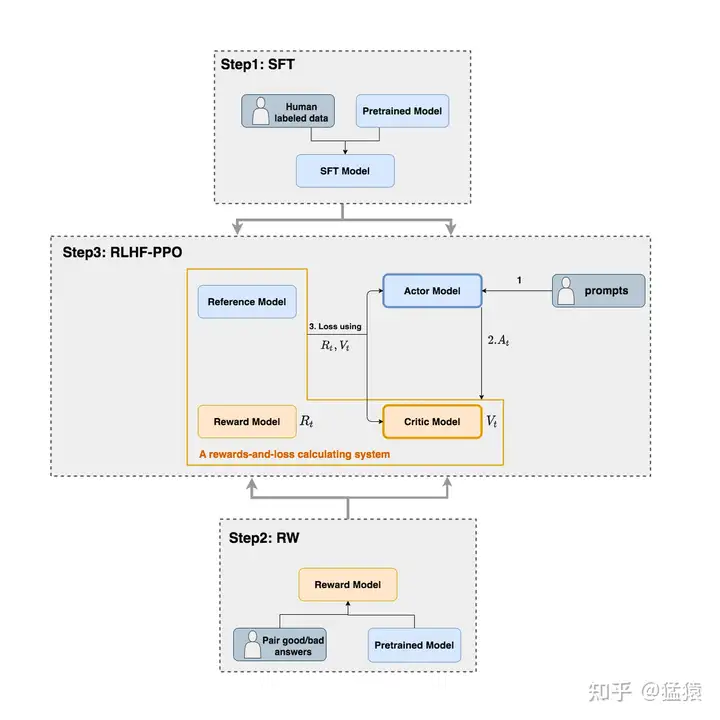
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
**Reference Model :**用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的

method:
ref_log_probs - log_probs 两者相近,说明两者分布类似Critic Model(评论家模型):
用于预测期望总收益目前状态下的总收益,和Actor模型一样,它需要做参数更新,也就是训练critics模型用于拟合真实人类对于当前内容生成的喜好。
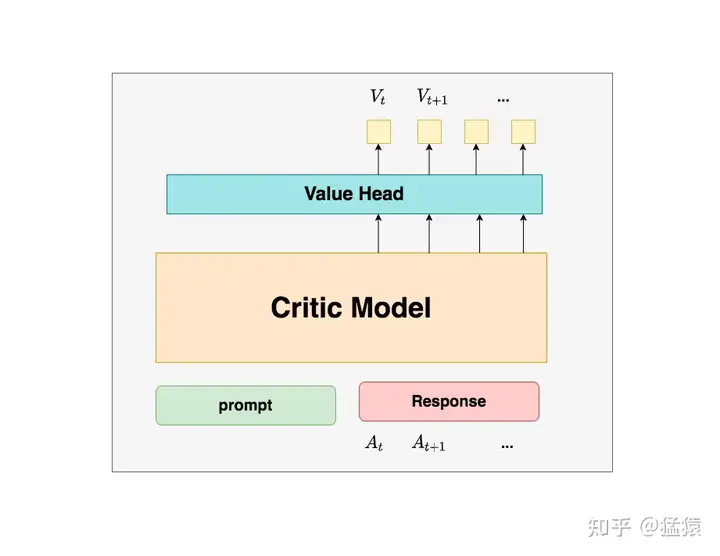
在最后一层增加了一个Value Head层,该层是个简单的线形层,用于将原始输出结果映射成单一的$V_t$值,表示当前以及未来的价值的总和状态
Reward Model(奖励模型):
它就是RW阶段所训练的奖励模型,在RLHF过程中,它的参数是冻结的。用于计算$token A_t$在生成后的即时收益,同时我们生成$R_t$与$V_{T+1}$ 和批判模型中生成的$V_t$做差